授業雑記
2024-06-27(木)




流行に流されて
ChatGPTが一般公開されたのが、2022年11月。私が使用したのが1か月後の12月でした。2023年の春頃になるとメディアでも頻繁に取り上げられるようになり、毎日のように使われている方も多いと思います。
しかし、Pythonをはじめとした言語からAPIを操作するとChatGPTをはじめとした大規模言語モデルの活用方法にも幅がでてきます。その1つがRAG(Retrieval Augmented Generation)です。大規模言語モデル(LLM)は膨大なデータを元に学習を行います。したがって、登場したばかりの技術は学習が不十分であったり、外部には公開できない組織内の文書は学習すらできません。こういう状況でRAGは活躍します。学習ではなく、最新のドキュメントや、指定したサイトを検索し、そこから答えは返してくれます。
私は技術系のPDFファイルを数千所有しています。それをChromaと呼ばれるデータベースに保存し、ChatGPTに対し、このデータベースを使って答えてとプログラミングすると、簡単に的確な答えを出してくれるので非常に重宝しています。
このように非常に便利な反面、料金が少しかさみます。ChatGPT、Gemini、Authropic Clade すべて優秀なLLMですが、料金が気になるところです。私たち技術者はオープンソースのLLMを使用してこのような悩みを解消しています。もともとFacebookが開発していたLlamaがオープンソース化されたので、自分のPCに取り込み使用しています。商用のLLMにはおよびませんが、RAGだけであれば使えるレベルです。また将来的にはもっといいオープンソースが出てくる可能性があります。プログラミングを学習すると、いつも一歩二歩先を行けます。どうでしょう?生成AIが出てきてもプログラミングの需要はなくなりはしないのです。
2023-06-12(月)Kubernetesその2


さらに先にすすめると
また、Kubernetesです。今度はEKS、AKS、GKEなどの大手クラウドベンダーを利用してのKubernetesではなく、素のサーバを数台借りて、kubeadmを使用してのKubernetesクラスタ作成の話です。前回紹介した「The Kubernetes Bible」では一旦クラスタができてしまえば、今は一から作る時代ではないような説明がありますが、一から作ることにより分かることがあるのではと思い、写真の「Advanced Platform Development with Kubernetes」を参考にチャレンジ中です。
まだ、p120あたりですが、この時点での感想は「一からつくる努力をしなくてもいいかもしれないが、見えてくるものはたくさんある。」ということです。このあたりに興味がある人は大いに挑戦してほしいところです。ただし、写真の本は2020年出版なのでおそらく2019年以前の情報が多くそのままではほぼ動きません。第2版を望むところですが、アマゾンのレビューもほとんどなく第2版はでないかもしれません。しかし、ネットワークやLinuxなどを少し知っていれば自力で解決できるところも多くありますので、そういう方にはまだ薦められるかと思います。
やはり一番重要なので、kubeadmを使って、マスターノード(Control Plane)からインストールできるところだと思います。大手クラウドベンダーはControl Planeに触ることができないところが多いようです。個別に借りたインスタンスを、どうすればクラスタとして構成できるかなどよく理解できるようになります。
この本の面白いところは最終的に「機械学習、ブロックチェーン、IoTに特価した、トレンド技術に取り組むためのデータドリブンな基盤を形成」しようとしているところです。
他書に多く見られるような、DeploymentやServiceのマニフェストの書き方からその適用の仕方などの細かい説明はありませんが、そこから先に進みたいのであれば是非おススメの本です。
ただし、ここまでの基盤を作るとなると少し大きめのコンピュータリソースが必要となるため、日々増えていくBilling情報を気にしつつの構築となります。4vCPU・4Gメモリインスタンス3個、3vCPU・4Gメモリインスタンスだと1日千円以上の料金が発生します。インスタンスの電源を落としても5百円です。ましてや基盤を完成させて本稼働となると1日1万くらいはかかりそうです。大手クラウドベンダーと比較すると安いのですが、勉強目的としては適していません。一旦ここでストップして、安い構築方法を模索することにします。
2023-05-10(水)Kubernetes


行き着くところはコンテナ・オーケストレーション
前回、前々回とコンテナ化のお話をしましたが、小規模システムではdocker composeあたりを使えばなんとか運用できます。しかし、大規模システムともなるとWebサーバだけでも数万台配置することもあります。もちろん、数万台のマシンを用意するのも容易ではありません。また、マシンにOSやミドルウェアをインストールし、そこからさらに細かな設定を数万台もれなく設定しなくてはなりません。手作業では不可能だといえるでしょう。
そので登場するのがKubernetesです。Kubernetes以外にもコンテナ・オーケストレーションツールはありましたが、今や一択といっても過言ではありません。クラウド、オンプレミス、ハイブリッド、マルチクラウドに関係なく、Kubernetesのようなツールは必須なのです。マシン(Node)上にPodを作成し、PodにDockerイメージからコンテナを作成するため、Webサーバの物理マシンを数万台用意する必要はなく、コンテナが数万台あれば事足ります。また、設定もマニュフェストファイルに記述するため、テストするたびに安定してきます。それを数万のコンテナに適用するだけなので、手作業とは比較にならない時間で数万台の構成が終わります。
もともとKubernetesは複雑な依存関係をコンテナ内に封じ込めための技術でもあります。コンテナはそれ自体が閉じた世界なのでプログラム言語やライブラリのバージョンなどが違っていても、Restに準拠した通信であれば、まったく影響を与えることがないのです。
さらにKubernetesはマイクロサービスを実現するという目的でも開発されてきたツールです。Restベースの通信をすることで、お互いのコンテナがどういう言語で作られているのかすら知らなくても、全体のシステムを構築できるということです。マイクロサービス化することで、IoTのデータをDeap LearningやBlock Chainに渡すフローも簡単に実装できるようになります。サービス同士の柔軟な組み合わせが可能となります。そういう意味では、大規模システムだけではなく小規模システムでも大いに利用する価値があると言えます。今ではシングルノードを想定したKubernetes準拠のコンテナ・オーケストレーションツールも存在します。Kubernetes界隈も成熟してきた感があります。
そうは言っても、業務ではログの収集・解析や、メトリクスを収集してシステム監視することまで考えると導入を躊躇するかもしれません。しかし、心配は無用です。helmを使ってコマンド一つで導入できます。ログに関してはElasticSearchやkibana、メトリクス収集・システム監視であればPrometheusをコマンド一つで導入できます。
メリットを挙げればきりがないですが、今や開発・運用においてなくてはならない存在となっています。実験的にある会社様に授業を行っていますが、興味がある方は個別にご相談ください。
2022-10-23(日)【Java・SpringBoot】コンテナ化


Dockerによるコンテナ化
前回、Laravelのコンテナ化の話をしましたが、先にSpring Bootをコンテナ化する必要が出てきたため、AWSのEC2上でコンテナ化し、無事動作確認まで出来ました。 VSCodeでMavenを使って開発していますが、Mavenをあまり意識することなく使っていたことに、今更ながら気づきました。mavenイメージをpullし、package化し、それをtomcatイメージに
WORKDIR /usr/local/tomcat/webapps/
COPY --from=maven ○○○.war ○○○.war
という方法にたどり着くまで、若干時間がかかってしまいました。いい勉強になりました。
現在、Docker Composeとkubernetesを勉強しているので、もう少し機能を追加し、再度、AWSまたはGCP上でコンテナオーケストレーションに挑戦したいと考えています。
KubernetesはGCP上で実験中ですが、gcloudコマンドを覚えきれないため、シェルを組み、クラスターの作成、Credentialの取得、クラスタの破棄を自動化することで、本来のKubernetesの習得に専念できるようになりました。
20年ぶりくらいのBashでのシェルスクリプトの作成、思った以上に苦戦してしまいました。やはり、言語は日ごろから慣れ親しむことが大切だと改めて感じました。
もう少し、訓練を積んだら、正式にコース化する予定です。
2022-08-02(火)【PHP・Laravel】コンテナ化
Dockerによるコンテナ化
今やコンテナは必須技術となりつつあります。さらにはKubernetesを使って、コンテナをまとめて操作できる時代になりました。
コンテナといわれても、AWSやAzureなどのクラウドのサービスだからプログラムに関係ないと思っている方もいるかもしれません。
しかし、今は開発自体もコンテナに移行しつつあります。コンテナのメリットは山ほどありますが、開発環境をホストマシンから隔離でき、ソフトウェア・ミドルウェア等のバージョンの違いによるプログラムの挙動の違いをなくすことが可能、ということでしょう。
現在、SpringBoot用のコンテナを作っています。出来上がったらSpringBootはコンテナを使った授業にしたいと考えています。その次はDjango位を考えています。
Laravelに至っては既にsailコマンドでコンテナのことを知らなくとも、簡単にWebサーバ、データベースサーバなど瞬時に起動することができて、既に授業でも使用しています。
みなさんも是非、コンテナベースでの開発にチャレンジしてください。ご要望があれば、コンテナを使った授業を実験的に取り入れようと考えています。
2021-09-09(木)【C言語】ハッシュテーブルを使用したSetの実装
C言語でJavaのHashSetに似たSetを実装
授業で使用しているC言語の参考書の集合の実装は非常にわかりやすいと思いますが、パフォーマンスが悪く実務レベルでは使用できないので、ハッシュテーブルを使用して実装してみました。
構造体として集合を表現してみました。以下が整数値を要素とする集合の構造体です。
/*--- int型の集合を実現する集合体 ---*/
typedef struct {
int num;
int size; // ハッシュテーブルのサイズ
Node **hash;
} HashSet;
HashSetのヘッダ
/*--- 集合の初期化 ---*/
int Initialize(HashSet *s, int size);
/*--- 集合sにnが入っているか ---*/
int IsMember(const HashSet *s, int n);
/*--- 集合sにnを追加 ---*/
void Add(HashSet *s, int n);
/*--- 集合sからnを削除 ---*/
void Remove(HashSet *s, int n);
/*--- 集合sに格納できる最大の要素数 ---*/
int Capacity(const HashSet *s);
/*--- 集合sの要素数 ---*/
int Size(const HashSet *s);
/*--- 集合sが満杯であれば1を、満杯でなければ0を返す ---*/
int IsFull(const HashSet *s);
/*--- 集合s2をs1に代入 ---*/
void Assign(HashSet *s1, const HashSet *s2);
/*--- 集合s1とs2は等しいか ---*/
int Equal(const HashSet *s1, const HashSet *s2);
/*--- 集合s2とs3の和集合をs1に代入 ---*/
HashSet *Union(HashSet *s1, const HashSet *s2, const HashSet *s3);
/*--- 集合s2とs3の積集合をs1に代入 ---*/
HashSet *Intersection(HashSet *s1, const HashSet *s2, const HashSet *s3);
/*--- 集合s2からs3を引いた集合をs1に代入 ---*/
HashSet *Difference(HashSet *s1, const HashSet *s2, const HashSet *s3);
/*--- 集合s2とs3の対称差をs1に代入する ---*/
HashSet *SymmetricDifference(HashSet *s1, const HashSet *s2, const HashSet *s3);
/*--- 集合s1に対して集合s2の全要素を追加する ---*/
HashSet *ToUnion(HashSet *s1, const HashSet *s2);
/*
集合s1から集合s2に含まれない要素を削除する
つまり、s1をs1とs2の積集合にする
*/
HashSet *ToIntersection(HashSet *s1, const HashSet *s2);
/*--- 集合s1に対して集合s2の全要素を追加する ---*/
HashSet *ToDifference(HashSet *s1, const HashSet *s2);
/*
集合s1がs2の部分集合であるかどうかを判定する
・部分集合である場合、1
・部分集合出ない場合、0
を返す
*/
int IsSubset(const HashSet *s1, const HashSet *s2);
/*
集合s1がs2の真部分集合であるかどうかを判定する
・真部分集合である場合、1
・真部分集合出ない場合、0
を返す
*/
int IsProperSubset(const HashSet *s1, const HashSet *s2);
/*--- 集合sの全要素を表示 ---*/
void Print(const HashSet *s);
/*--- 集合sの全要素を表示(改行付き) ---*/
void PrintLn(const HashSet *s);
/*--- 集合sが内部で使用しているハッシュテーブルの表示 ---*/
void PrintHash(const HashSet *s);
/*--- 集合の後始末 ---*/
void Terminate(HashSet *s);
Intersectioの実装は以下のようになります。要素と比較してハッシュテーブルのサイズが大きすぎたり、小さすぎるとパフォーマンスは落ちます。動的にテーブルサイズを変更できるようにすべきですが、今回は行っていません。
/*--- 集合s2とs3の積集合をs1に代入 ---*/
HashSet *Intersection(HashSet *s1, const HashSet *s2, const HashSet *s3)
{
int i;
for (i = 0; i < s2->size; i++) {
Node *temp = s2->hash[i];
while (temp != NULL) {
if (IsMember(s3, temp->val)) {
Add(s1, temp->val);
}
temp = temp->next;
}
}
return s1;
}
JavaのSetには集合演算はありませんが、簡単に実装できるのであえて用意していないのかもしれません。今回の実装は、JavaのHashSetと同等レベルのパフォーマンスとなります。ただしJavaのHashSetのコードを見るとわかりますが、要素数の調整がきちんと実装されており、そのあたりまで考慮すると、JavaのHashSetは非常に優秀な作りです。みなさんもUnion、Differenceの実装にチャレンジしてみてください。
2020-11-19(木)【Python】Set
集合演算としての集合
JavaなどのようにSetと名の付くコレクションクラスでも集合演算を直接サポートしない言語もあります。もちろん、Javaでもメソッドレベルであれば集合演算を自分で作れますが、やはり面倒に思えます。それに対しPythonは演算子レベルでサポートしており直感的で使いやすくなっています。
以下は、積集合(intersection)、和集合(union)、差集合(difference)、排他的和集合(symmetric difference)をテストしたものです。少し面白みに欠けますがご参考までに。
s1 = {1, 2, 3, 4, 5, 6}
s2 = {1, 2, 4, 8, 16}
s9 = {2, 4, 6, 8}
print('===< intersection >===\n')
print('---< s3 = s1 & s2 >---')
s3 = s1 & s2
print('s1 =', s1)
print('s2 =', s2)
print('s3 =', s3)
print('---< s3 = s1.intersection(s2) >---')
s3 = s1.intersection(s2)
print('s1 =', s1)
print('s2 =', s2)
print('s3 =', s3)
print('---< s3 = s1.intersection(s2, s9) >---')
s3 = s1.intersection(s2, s9)
print('s1 =', s1)
print('s2 =', s2)
print('s9 =', s9)
print('s3 =', s3)
print('---< s1 &= s2 >---')
s1 &= s2
print('s1 =', s1)
print('s2 =', s2)
print('s3 =', s3)
print('---< s1 = {1, 2, 3, 4, 5, 6} >---')
s1 = {1, 2, 3, 4, 5, 6}
print('--- s1.intersection_update(s2, s9) >---')
s1.intersection_update(s2, s9)
print('s1 =', s1)
print('s2 =', s2)
print('s9 =', s9)
print('\n===< union >===\n')
print('---< s1 = {1, 2, 3, 4, 5, 6} >---')
s1 = {1, 2, 3, 4, 5, 6}
print('---< s3 = s1 | s2 >---')
s3 = s1 | s2
print('s1 =', s1)
print('s2 =', s2)
print('s3 =', s3)
print('--- s3 = s1.union(s2) >---')
s3 = s1.union(s2)
print('s1 =', s1)
print('s2 =', s2)
print('s3 =', s3)
print('---< s1 |= s2 >---')
s1 |= s2
print('s1 =', s1)
print('s2 =', s2)
print('---< s1 = {1, 2, 3, 4, 5, 6} >---')
s1 = {1, 2, 3, 4, 5, 6}
print('---< s1.update(s2, s9) >---')
s1.update(s2, s9)
print('s1 =', s1)
print('s2 =', s2)
print('s9 =', s9)
print('\n===< difference >===\n')
print('---< s1 = {1, 2, 3, 4, 5, 6} >---')
s1 = {1, 2, 3, 4, 5, 6}
print('---< s3 = s1 - s2 >---')
s3 = s1 - s2
print('s1 =', s1)
print('s2 =', s2)
print('s3 =', s3)
print('---< s3 = s1.difference(s2, s9) >---')
s3 = s1.difference(s2, s9)
print('s1 =', s1)
print('s2 =', s2)
print('s9 =', s9)
print('s3 =', s3)
print('---< s1 -= s2 >---')
s1 -= s2
print('s1 =', s1)
print('s2 =', s2)
print('---< s1 = {1, 2, 3, 4, 5, 6} >---')
s1 = {1, 2, 3, 4, 5, 6}
print('---< s1.difference_update(s2, s9) >---')
s1.difference_update(s2, s9)
print('s1 =', s1)
print('s2 =', s2)
print('s9 =', s9)
print('---< s1 = {1, 2, 3, 4, 5, 6} >---')
s1 = {1, 2, 3, 4, 5, 6}
print('---< s3 = s1.symmetric_difference(s2) >---')
s3 = s1.symmetric_difference(s2)
print('s1 =', s1)
print('s2 =', s2)
print('s3 =', s3)
print('===< symmetric differecnce >===')
print('---< s3 = s1 ^ s2 >---')
s3 = s1 ^ s2
print('s1 =', s1)
print('s2 =', s2)
print('s3 =', s3)
print('---< s1 ^= s2 >---')
s1 ^= s2
print('s1 =', s1)
print('s2 =', s2)
print('---< s1 = {1, 2, 3, 4, 5, 6} >---')
s1 = {1, 2, 3, 4, 5, 6}
print('---< s1.symmetric_difference_update(s2) >---')
s1.symmetric_difference_update(s2)
print('s1 =', s1)
print('s2 =', s2)
print('\n===< disjoint ===\n')
print('---< s4.isdisjoint(s5) >---')
s4 = {1, 3, 5, 7, 9}
s5 = {2, 4, 6, 8, 10}
print('s4 =', s4)
print('s5 =', s5)
print('s4.isdisjoint(s5) =>', s4.isdisjoint(s5))
print('s5 =', s5)
print('\n===< contains ===\n')
n1 = 5
n2 = 6
print('n1 =', n1)
print('n2 =', n2)
print('---< n1 in s4 >---')
print('n1 in s4 =>', n1 in s4)
print('---< n2 in s4 >---')
print('n2 in s4 =>', n2 in s4)
print('\n===< subset >===\n')
s6 = {2, 4, 6, 8, 10}
print('s6 =', s6)
print('s5 <= s6 =>', s5 <= s6)
print('\n===< proper subset >===\n')
s0 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
print('s0 =', s0)
print('s4 < s0 =>', s4 < s0)
print('s5 < s0 =>', s5 < s0)
print('\n===< superset >===\n')
s6 = {2, 4, 6, 8, 10}
print('s6 =', s6)
print('s5 >= s6 =>', s5 >= s6)
print('\n===< proper superset >===\n')
print('s0 =', s0)
print('s0 > s4 =>', s0 > s4)
print('s0 > s5 =>', s0 > s5)
2020-04-27(月)【JavaScript】オブジェクトの分割代入
分割代入
以下のようにname、height、weightを持ったオブジェクトの配列があるとします。身長(height)と体重(weight)からBMI値を求める関数を作る場合、昔の書き方であれば、オブジェクトからheightとweightを取り出しbmi関数を呼び出していました。
ES2015以降はオブジェクトの分割代入を使うとシンプルな実装ができるようになりました。bmi関数の引数をheightとweightを持ったオブジェクトとして定義すると、関数を呼び出す側、もしくは関数側でオブジェクトからheightとweightを取り出す必要がなくなりました。
呼び出し側で呼び出す関数の引数であるオブジェクトのキー名を知っている必要はありますが、シンプルな呼び出しができます。
let members = [
{ name: '山田太郎', height: 172, weight: 81, age: 25 },
{ name: '横山花子', height: 162, weight: 55, age: 28 },
{ name: '田中一郎', height: 178, weight: 77, age: 35 },
{ name: '山本久美子', height: 155, weight: 50, age: 30 }
];
// 引数がheightとweightの並びではなくオブジェクトであることに注意
const bmi = ( { height, weight } ) => weight / (height / 100) ** 2;
for (let member of members) {
console.log(member['name'] + ':' + bmi(member).toFixed(1));
}
2020-03-09(月)【C言語】高階関数
高階関数
C言語のポインタは変数だけでなく、文字列リテラルや関数へのポインタも生成することが可能です。
関数のポインタを使えば、非常に柔軟な関数を作成することが可能になります。普通の関数を定義しているうちに、同じような定義が何度も出てきた場合、それは高階関数化するシグナルです。
以下のコードは整数の配列を受け取り、ある条件を満たす整数のみの合計も求める関数です。条件が変わるだけで関数を定義していては同じアルゴリズムを持った関数が複数定義されてしまいます。バグ修正、仕様変更があった場合、修正コスト・テストコストが定義した関数に比例することになり大きな問題となります。このような場合、条件を関数化し、それを引数として使用する関数に渡すことで大枠の関数を再利用できます。このように引数として関数を受け取る関数を高階関数(higher-order function)と呼びます。
関数へのポインタを別の関数の引数として渡すことでC言語は高階関数を作ることができます。
#include <stdio.h>
int even(int n)
{
return n % 2 == 0;
}
int gt_zero(int n)
{
return n > 0;
}
int mysum(const int *a, size_t n, int (*func_ptr)(int))
{
int i;
int total = 0;
for (i = 0; i < n; i++) {
if (func_ptr(a[i])) {
total += a[i];
}
}
return total;
}
int main(void)
{
int size;
int (*filter)(int);
int nums[] = { -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
size = sizeof(nums) / sizeof(nums[0]);
printf("偶数の合計: %d\n", mysum(nums, size, even));
printf("正の合計: %d\n", mysum(nums, size, gt_zero));
return 0;
}
2019-12-25(水)【C言語】乗算
乗算器を加算器を使って実装
12月8日の授業雑記で全加算器を紹介しました。実はコンピュータ内で乗算器は加算器から作ることが可能です。
乗算(mul)関数の実装例は以下の通りです。やはりビット演算とシフト演算以外は出てきません。今回はbit表現は必要としませんので、unsigned short int型ではなくunsigned int型を使用します。
#include <stdio.h>
unsigned int full_adder(unsigned int n1, unsigned int n2, unsigned int carry_out)
{
int i;
unsigned int result = 0;
unsigned int sum;
unsigned int tmp1, tmp2;
unsigned int mask = 1;
for(i = 0; i < 32; i++) {
tmp1 = n1 & mask;
tmp2 = n2 & mask;
sum = tmp1 ^ tmp2 ^ carry_out;
carry_out = tmp1 & tmp2 | tmp2 & carry_out | carry_out & tmp1;
result = result | (sum << i);
n1 >>= 1;
n2 >>= 1;
}
return result;
}
unsigned int mul(unsigned int n1, unsigned int n2)
{
int cnt = 0;
unsigned int result = 0;
unsigned int tmp = n2;
unsigned int last_bit = 1;
while (tmp) {
if (tmp & last_bit) {
result = full_adder(result, n1 << cnt, 0);
}
tmp >>= 1;
cnt++;
}
return result;
}
int main(void)
{
unsigned int a;
unsigned int b;
printf("unsigned int a:");
scanf("%u", &a);
printf("unsigned int b:");
scanf("%u", &b);
unsigned int c = mul(a, b);
printf("%u * %u = %u\n", a, b, c);
return 0;
}
2019-12-08(日)【C言語】全加算器
全加算器の概念をC言語で表現
1か月ほど前から、コンピュータの基礎から教えてほしいとの要望に応え、ディジタル回路、ゲート回路から始め、今は全加算器の説明に入るところです。絵で見ても概念は掴めるかと思いますが、C言語で表現するとどうなるのか挑戦しました。
正確には「桁上げ伝播加算器」と呼ぶようですが、一番下の桁には下位桁からの桁上りはありませんが、加算の場合は0、減算の場合は1を入力します。減算の場合は、全加算器にビットを論理否定したものを入力します。そうですね、論理否定したものに1を加算する、これが情報処理試験などで勉強する2の補数となります。うまく考えてあるなと感心します。
以下はそのコードですが、完全な出来ではないのですが、加算・減算の雰囲気をつかんでいただければと思い掲載します。
#include <stdio.h>
unsigned int full_adder(unsigned int n1, unsigned int n2, unsigned int carry_out)
{
int i = 0;
unsigned int mask = 1;
unsigned int tmp1, tmp2;
unsigned int result = 0;
// 32固定ではなく、ここもビット操作で求めることが可能
for (i = 0; i < 32; i++) {
tmp1 = n1 & mask;
tmp2 = n2 & mask;
result = result | ((tmp1 ^ tmp2 ^ carry_out) << i);
carry_out = tmp1 & tmp2 | tmp2 & carry_out | carry_out & tmp1;
n1 >>= 1;
n2 >>= 1;
}
return result;
}
int main(void)
{
unsigned int a, b;
puts("2つの符号なし整数の和を計算します。");
printf("unsigned int a:");
scanf("%u", &a);
printf("unsigned int b:");
scanf("%u", &b);
// 加算 a + b
unsigned int carry_out = 0;
unsigned int c = full_adder(a, b, carry_out);
printf("%u + %u = %u\n", a, b, c);
// 減算 a - b
carry_out = 1;
// 本来はfull_adder関数の中でビットの反転をすべきところだが・・・
// aがbより大きいと仮定
c = full_adder(a, ~b, carry_out);
printf("%u - %u = %u\n", a, b, c);
return 0;
}
2019-10-09(水)【C言語】時刻関数抜きでのカレンダー作成
ISBN
柴田望洋先生の「新・明解C言語 入門編」p269の演習問題10-2は西暦の年月日の前日、翌日を求める問題です。ポインタの問題ですが、PythonのcalendarモジュールにTextCalendarクラスがあります。そのクラスのprmonthみたいなものを作ってみました。
時刻関数は一切使っていません。閏年の判定、曜日(0から6の数値、0が日曜日となる)の取得、数値の曜日から日本語の曜日に変換する関数を新たに追加し、演習問題の前日、翌日を求める関数を組み合わせると、prmonth関数は意外と簡単にできます。
授業では市販の参考書を使用していますが、そこからどんどん新しい問題を即興で考えてはその場で解いています。楽しい時間です。
#include <stdio.h>
#define NEXT 1
#define PREV 2
#define MONTHS 12
#define YMD 3
int month_ends[][MONTHS + 1] = {
{ 0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 },
{ 0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 },
};
int is_leap_year(int year) {
return year % 4 == 0 && year % 100 != 0 || year % 400 == 0;
}
int is_valid_date(int y, int m, int d)
{
int n = is_leap_year(y);
if (m > MONTHS || d > month_ends[n][m]) {
printf("%d年%d月%d日は暦上存在しません。\n", y, m, d);
return 0;
}
return 1;
}
int decrement_date(int *y, int *m, int *d)
{
int n; // うるう年:1 うるう年でない:0
int prev_month_end;
if (!is_valid_date(*y, *m, *d)) {
return 0;
}
n = is_leap_year(*y);
if (*d == 1) {
if (*m == 1) {
(*y)--;
*m = 12;
} else {
(*m)--;
}
*d = month_ends[n][*m];
} else {
(*d)--;
}
return 1;
}
int increment_date(int *y, int *m, int *d)
{
int n; // うるう年:1 うるう年でない:0
if (!is_valid_date(*y, *m, *d)) {
return 0;
}
n = is_leap_year(*y);
if (*d == month_ends[n][*m]) { // 月末判定
if (*m == 12) {
(*y)++;
*m = 1;
} else {
(*m)++;
}
*d = 1;
} else {
(*d)++;
}
return 1;
}
void test(int days[][YMD], int size, int sw, char *desc1, char *desc2)
{
printf("\n===< %s >===\n", desc1);
printf("---< %s >---\n", desc2);
int i, j, result, year, month, day;
for (i = 0; i < size; i++) {
year = days[i][0];
month = days[i][1];
day = days[i][2];
printf("%d年%02d月%02d日 ---> ", year, month, day);
if (sw == NEXT) {
if (increment_date(&year, &month, &day)) {
printf("%d年%02d月%02d日\n", year, month, day);
} else {
putchar('\n');
}
} else if (sw == PREV) {
if (decrement_date(&year, &month, &day)) {
printf("%d年%02d月%02d日\n", year, month, day);
} else {
putchar('\n');
}
}
}
}
int get_day_of_week( int year, int month, int day )
{
if( month < 3 ) {
year--;
month += 12;
}
return (year + year / 4 - year / 100 + year / 400 +\
(13 * month + 8) / 5 + day) % 7;
}
char *get_day_of_week_ja(int wday)
{
char *wday_name;
char *weekdays[] = {
"日", "月", "火", "水", "木", "金", "土"
};
wday_name = (char *)weekdays[wday];
// printf("wday=%d wday_name=%s\n", wday, wday_name);
return wday_name;
}
void prmonth(int year, int month)
{
int i, padding, init_month = month, day = 1;
char *format;
printf(" %d年%d月 \n", year, month);
printf("日 月 火 水 木 金 土\n");
int wday = get_day_of_week(year, month, day);
for (padding = 0; padding < wday; padding++) {
format = padding == 0 ? "%2s": "%3s";
printf(format, " ");
}
while (init_month == month) {
format = wday == 0 ? "%2d": "%3d";
printf(format, day);
if (wday == 6) {
printf("\n");
}
increment_date(&year, &month, &day);
wday = get_day_of_week(year, month, day);
}
putchar('\n');
}
int main(void)
{
// printf("%s曜日\n", get_day_of_week_ja(6));
int init_year, year, month, day, count = 0;
printf("カレンダーを表示します。\n年と月を整数で入力してください:");
scanf("%d %d", &year, &month);
prmonth(year, month);
return 0;
}
2019-9-16(月)【Python】ISBNチェックディジット
ISBN
ISBNコードの最後の桁はチェックディジットと呼ばれ、コードが形式上正しいかを判断するためのものです。 書籍コードとして正しいかまでは判定できませんが、入力ミスのチェックくらいには使用可能です。 以下のコードがISBNのチェック関数となります。引数のバリデーション機能は入れていません。
def isbn_check(isbn):
total = 0
isbn = isbn.replace('-', '')[0:-1]
for i, n in enumerate(isbn):
n = int(n)
total += n if i % 2 == 0 else n * 3
return 10 - (10 if total % 10 == 0 else total % 10)
isbns = ['978-4-7741-5377-3',
'978-4-7980-5347-9',
'978-4-7981-4461-0']
for isbn in isbns:
print('isbn={}, actual={}, expected={}'.format(\
isbn, isbn_check(isbn), isbn[-1]))
2019-9-12(木)【Python】自作クラスのソート
Pythonの場合
私がPythonを使いだしたのが1992年頃。その頃はまだPythonはラムダ式を持っていませんでした。私の記憶によれば、バージョン1からラムダ式を持つようになったはずで随分歴史があります。私にとって一番なじみのある書き方ですが、今となってはlambdaという言葉さえ不要だと考える人が多くなったのではないでしょうか。
以下はJavaの例と同じことを確認するために、get_bmiメソッドを持つMemberクラスを定義した後、Memberインスタンスのlistを、ラムダ式を使用してBMI順にソートできることを示しています。
他の言語と同じようにlistのsortメソッドは破壊的ですが、sort関数は非破壊的なので、元の並び順を変えたくない場合はsort関数を使うこともできます。
class Member:
def __init__(self, name, height, weight):
self.__name = name
self.__height = height
self.__weight = weight
@property
def name(self):
return self.__name
@property
def height(self):
return self.__height
@property
def weight(self):
return self.__weight
def get_bmi(self):
return self.weight / (self.height / 100) ** 2
def __str__(self):
return "Member [name={}, height={:.1f} weight={:.1f}".\
format(self.name, self.height, self.weight)
from member import Member
members = [
Member("山田太郎", 170, 70),
Member("田中次郎", 170, 65),
Member("鈴木三郎", 170, 80),
Member("佐藤四郎", 170, 75)
]
def print_members(mems):
for member in mems:
print(member)
print("------< ソート前 >------")
print_members(members)
members.sort(key=lambda m: m.get_bmi())
print("------< BMI値でソート >------")
print_members(members)
2019-9-6(金)【Java】自作クラスのソート
Javaの場合(Java8以降)
Java8以降になりラムダ式が導入され、Javaもようやく高階関数を作りやすくなりました。
前回のMemberクラスのListをBMI順にソートするプログラムもラムダ式を使うと以下のように非常にシンプルに書けるようになりました。
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
public class MemberBmiComparatorLambdaTest {
public static void main(String[] args) {
List members = Arrays.asList(
new Member("山田太郎", 170, 70),
new Member("田中次郎", 170, 65),
new Member("鈴木三郎", 170, 80),
new Member("佐藤四郎", 170, 75)
);
System.out.println("------< ソート前 >------");
printMembers(members);
Collections.sort(members, (m1, m2) ->
Double.compare(m1.getBmi(), m2.getBmi())
);
System.out.println("------< BMI値でソート >------");
printMembers(members);
}
private static void printMembers(List members) {
for (Member m: members) {
System.out.println(m);
}
}
}
2019-9-4(水)【Java】自作クラスのソート
Javaの場合(Java7以前)
Java7以前はラムダ式がないため、メソッドの引数としてロジックを流し込むにはインターフェースを使用して渡す必要があります。
今回はMemberクラスのListをBMI値の昇順にソートするプログラムを作成します。ただ、JavaのListにはソート機能はなく、Collectionsのsortメソッドの引数にListを渡すことでソートします。
ソートする基準が数値や文字列の場合は簡単なのですが、自作したクラスをCollectionsのsortメソッドに渡しても、Collectionsは何を基準にソートしていいか分かりません。Collectionsのsortメソッドの第2引数はそのソート基準を伝えるためのオブジェクト渡すことになります。そのオブジェクトのクラスはComparatorインターフェースを実装する必要があります。
Comparatorインターフェースはcompareメソッドを持っています。compareメソッドはListの要素の型を2つ受け取り、第1引数と第2引数をある基準で比較し、第1引数の方が小さい場合は負の整数値を、大きい場合は正の整数値を、等しい場合は0を返します。
Memberクラスは身長(cm)と体重(kg)のフィールドを持ち、それを元にBMI値を求めるgetBmiメソッドを持っています。したがって、sortメソッドの第2引数にはBMI値でソートするよう定義したComparatorの実装オブジェクトを渡します。
以下のプログラムはMemberオブジェクトを格納したListオブジェクトをBMI順にソートする例となります。
public class Member {
private String name;
private double height;
private double weight;
public Member(String name, double height, double weight) {
this.name = name;
this.height = height;
this.weight = weight;
}
public String getName() {
return name;
}
public double getHeight() {
return height;
}
public double getWeight() {
return weight;
}
public double getBmi() {
return weight / Math.pow(height / 100, 2);
}
@Override
public String toString() {
return "Member [name=" + name + ", height=" + height + ", weight=" + weight + "]";
}
}
import java.util.Comparator;
public class MemberBmiComparator implements Comparator{
@Override
public int compare(Member o1, Member o2) {
return Double.compare(o1.getBmi(), o2.getBmi());
}
}
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
public class MemberBmiComparatorTest {
public static void main(String[] args) {
List members = Arrays.asList(
new Member("山田太郎", 170, 70),
new Member("田中次郎", 170, 65),
new Member("鈴木三郎", 170, 80),
new Member("佐藤四郎", 170, 75)
);
System.out.println("------< ソート前 >------");
printMembers(members);
Collections.sort(members, new MemberBmiComparator());
System.out.println("------< BMI値でソート >------");
printMembers(members);
}
private static void printMembers(List members) {
for (Member m: members) {
System.out.println(m);
}
}
}
2019-7-23(火) 【Python】ちょっとオブジェクト指向
今日の授業はクラス設計の入り口当たりのこと生徒さんに考えてもらいました。頭の中ではオブジェクト指向は分かっているものの、いざ作ろうとすると手が止まってしまいがちです。
最初は不格好でもいいから、思った通りにクラスを作ってもらっており、その後徐々に改良すればいいことを体得して頂ければと思っています。以下は単語帳アプリのクラスで、WordクラスとWordListクラスだけですが、最初はこれで十分です。これに肉付けしていく過程の試行錯誤が重要だということを教えています。
WordListの内容をファイルまたはデータベースからの読み書きができるようになれば、ちょっとしたアプリが出来上がるはずです。これをPyQtでGUIにするか、DjangoでWebアプリにするかはたいして難しい話ではありません。
クラスを別ファイルに分割し、モジュールとしてimportしたり、Dictionaryあたりの記述をもっとすっきり書けるようにするあたりを次の授業にでも教えようと思っています。
class Word:
def __init__(self, english, japanese, pos):
self.english = english
self.japanese = japanese
if pos == '1':
tmp = '名詞'
elif pos == '2':
tmp = '動詞'
elif pos == '3':
tmp = '形容詞'
elif pos == '4':
tmp = '助動詞'
elif pos == '5':
tmp = '副詞'
self.pos = tmp
self.explist = []
#self.read_exp_list()
def add_exp(self, exp):
self.explist.append(exp)
def __str__(self):
print('english={}, japanese={}, pos={}'.format(self.english, self.japanese, self.pos))
for i, exp in enumerate(self.explist):
return str(i + 1) + ':' + exp
class WordList:
wordlist = {}
def add(word):
if word.english not in WordList.wordlist:
WordList.wordlist[word.english] = {}
WordList.wordlist[word.english][word.pos] = word
else:
if word.pos not in WordList.wordlist[word.english].keys():
WordList.wordlist[word.english][word.pos] = word
else:
WordList.wordlist[word.english][word.pos].explist += word.explist
def search(search_word):
if search_word in WordList.wordlist:
return WordList.wordlist[search_word]
while(True):
print('単語を登録します。終了するには「💤」を入力してください')
english = input('英単語 > ')
if english == 'zzz':
break
japanese = input('日本語 > ')
pos = input('品詞 1:名詞 2:動詞 3:形容詞 4:助動詞 5:副詞 > ')
word = Word(english, japanese, pos)
exp = input('例文 > ')
word.add_exp(exp)
WordList.add(word)
while(True):
print('単語を検索します。終了するには「zzz」を入力してください')
english = input('英単語 > ')
if english == 'zzz':
break
target_word = WordList.search(english)
if target_word is not None:
for word_pos in target_word.items():
print('品詞:{}'.format(word_pos[0]))
print('日本語:{}'.format(word_pos[1].japanese))
for i, exp in enumerate(word_pos[1].explist):
print('{}:{}'.format(i+1, exp))
2018-7-6(金) 【C言語】文字列操作
C言語を学習する中での最大の難関はなんと言ってもポインタだと思います。ポインタなんてなくなればいいのにと思っている方も多いかと思います。しかし、C言語の強みであるアドレスを意識できる細かい操作を可能にしているのはポインタです。是非、習得してC言語と仲良くなりましょう。
「新・明解C言語 ポインタ完全攻略」をC言語中級コースの参考書にしようと考えています。今日はその本のp132のList 4-41を参考にポインタの使い方の一例を紹介します。
C言語の標準ライブラリstring.hの中にstrstr関数があります。第1引数の文字列の中に第2引数の文字列が何番目に存在するかを調べる関数です。戻り値はchar型オブジェクトへのポインタ型です。
char *strstr(const char *s1, const char *s2)
が関数のシグネチャです。参考書はこの関数の疑似的な関数を紹介し、ポインタの理解を深めようとしています。しかし、これが難しい。以下がそのコードです。
char *strstr2(const char *s1, const char *s2)
{
const char *p1 = s1; // (1)
const char *p2 = s2; // (2)
while(*p1 && *p2) { // (3)
if (*p1 == *p2) { // (4)
p1++; // (5)
p2++; // (6)
} else {
p1 -= p2 - s2 - 1; // (7)
p2 = s2; // (8)
}
}
return *p2 ? NULL : (char *)(p1 - (p2 - s2)); // (9)
}
いかがでしょうか? 「*」がたくさん出てきて混乱しそうですね。「*」が曲者で、char *s1などのように記述する場合は、型宣言しており、s1がchar型オブジェクトへのポインタ型であることを示し、単に*s1と記述すると「参照外し」と呼ばれる、ポインタが指し示す内容となります。
(1)はs1をp1にコピーしています。p1の宣言で型がchar *となっている通り、s1と同じ型であることがわかります。p1はs1の文字列の先頭から1文字ずつ末尾に向かって進めていくために使用されます。
(2)は(1)と同様、検索対象の文字列のポインタをp2にコピーしています。
(3)はp1またはp2の内容、つまり*p1と*p2が両方が'\0'でない場合、処理を進めるという条件式です。ただし、この段階で文字列が見つかったかはまだ判断できません。判断は(9)で行っています。
(4)はp1またはp2の内容、つまり*p1と*p2が等しいかを判定しています。
(5)と(6)は等しい時の処理で、p1とp2を1つ先に進めています。
(7)と(8)は等しくない時の処理です。(7)は少し難しいですね。「p2 - s2」の理解ができるかがこの関数のポイントになります。s2は検索文字列の元のポインタです。それに対し、p2は(6)でs2よりも先に進んでしまっています。したがって「p2 - s2」は何個分先に進んだかを計算しています。実はこの時点でp1もこの値と同じ分だけ先に進んでしまっています。つまり「p1 -= p2 - s2」でp1を元のところまで戻しています。「p1 -= p2 - s2 - 1」の「-1」は完全に元に戻すと意味がないので1つ先に進めるためのものです。-1を引いているから+1足す結果となります。
(8)はp2を元のs2に戻し、最初から検索できるようにする処理です。
(9)はwhileを抜け出た時点でp2の内容(*p2)がまだ残っているようであれば、s1中にs2が見つからなかったことを意味しNULLを、見つかった場合は、(8)の理屈と同じで、検索のためにs2の文字数分先に進んでいますので、それを戻す処理です。 つまり、s1の中のs2が出現する最初の位置を計算しています。それをchar *型へ型変換して戻り値としています。
文字列だけの説明となりましたが、図に書き起こしてみれば理解できるようになります。是非、チャレンジしてください。
2018-5-26(金) 【JavScript・jQuery】DOM操作
5月16日の解答例です。既存のDOMに繰り返し構文で追加しています。本来であれば、既存のDOMに存在しないNodeを作り出し、JavaScriptでいうFragmentに追加すべきでしょうが、大目に見てください。
今回の問題のポイントはappendメソッドの戻り値がthisであるということを理解しているかという点です。したがって、append内部でさらにjQueryオブジェクトを生成しているのは、子のNodeを親に追加するためです。.appendメソッドがチェーンになっている場合、大元のjQueryオブジェクトへの操作となります。
以下にコードを載せていますので、上記のことに留意しながら試してもらえたらと思います。
$(function(){
$('#search').click(function() {
for (var i = 0; i < members.length; i++) {
$('#member-list')
.append($('<tr></tr>')
.append($('<td></td>').text(members[i]['name']))
.append($('<td></td>').text(members[i]['age']))
.append($('<td></td>').text(members[i]['gender']))
.append($('<td></td>').text(members[i]['height']))
.append($('<td></td>').text(members[i]['weight']))
);
}
});
});
2018-5-16(水) 【JavScript・jQuery】DOM操作
データベースやWebAPIを通じて取得したオブジェクトの配列を使って表形式で表示する問題です。今ではJavaScriptの優れたフレームワークがあるからそれで済みますが、ここは参照とは何か、DOMとは何かを意識してもらうための問題です。
以下のコードはjQueryのDOM操作を省略しています。以下のような表ができればOKです。是非、チャレンジしてください。
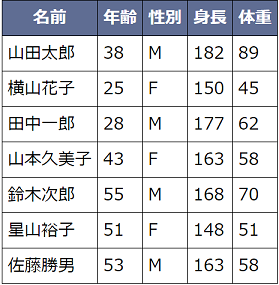
<script type="text/javascript" src="../jquery-2.0.3.min.js"></script>
<script>
var members = [
{'name': '山田太郎', 'age': 38, 'gender': 'M', 'height': 182, 'weight': 89},
{'name': '横山花子', 'age': 25, 'gender': 'F', 'height': 150, 'weight': 45},
{'name': '田中一郎', 'age': 28, 'gender': 'M', 'height': 177, 'weight': 62},
{'name': '山本久美子', 'age': 43, 'gender': 'F', 'height': 163, 'weight': 58},
{'name': '鈴木次郎', 'age': 55, 'gender': 'M', 'height': 168, 'weight': 70},
{'name': '星山裕子', 'age': 51, 'gender': 'F', 'height': 148, 'weight': 51},
{'name': '佐藤勝男', 'age': 53, 'gender': 'M', 'height': 163, 'weight': 58},
]
$(function(){
});
</script>
</head>
<body>
<input type="button" id="search" value="検索" />
<table border="1">
<thead>
<tr><th>名前</th><th>年齢</th><th>性別</th><th>身長</th><th>体重</th></tr>
</thead>
<tbody id="member-list">
</tbody>
<tfoot></tfoot>
</table>
2018-5-7(月) 【C#・アルゴリズム】二分探索(バイナリサーチ)
C#のSetはPython同様、和・積・差演算や部分集合の判定など非常に充実しています。それ以外にも高速に検索する能力も持っています。それを実感してもらうためにListでの線型検索と対比します。計算量としてはListはO(N)、SetはO(1)となりデータ量が多くなるほど顕著な差が出ます。
とは言え、Listの線形検索だとあまりにも比較にならないため、ListにもBinarySearchがありますが、アルゴリズムにも興味を持ってほしいため久しぶりに自作してみました。
授業では、Setの構築、Listのソート時間も実感してもらうようにしています。これらを加味して自分の解きたい問題にふさわしいコレクションクラスを選択できるようになるからです。
static bool MyBinarySearch(List list, int r)
{
int left = 0;
int right = list.Count - 1;
while(left <= right)
{
int mid = (left + right) / 2;
if (list[mid] == r)
{
return true;
}
else if(list[mid] > r)
{
right = mid - 1;
}
else
{
left = mid + 1;
}
}
return false;
}
2018-5-3(木) 【Python・統計学】平均・分散を求める
4月からある一人の生徒さんに「Think Stats」(原著の方を使用)という本でPythonを使って統計学を教える予定でした。しかし、NumPyやpandasを知らないとわからない部分が増え始めたため「Learning Pandas Second Edition」を使って、pandasの基礎を勉強中です。これは「NumPy・pandas・matplotlib」コースとは違い、純粋に統計学を勉強するための特別なコースです。
統計学といっても非常に奥が深いですが、まずは記述統計学を勉強しています。平均・分散・標準偏差などの指標を求める統計学と考えてください。もちろんPythonにはすぐれたモジュールが豊富に存在しており、pandasにもSeriesやDataFrameというクラスが存在し、簡単な指標であればメソッド一つで求めることが可能です。
そこを敢えてPythonの組み込み関数やクラスだけで求めています。以下の手順で進めていきます。
- for文を使う
- sum関数を使う
- リストの内包表記とsum関数を使う
(1)for文を使う
numbers = [3, 5, 6, 6, 10]
sum = 0
for num in numbers:
sum += num
avg1 = sum / len(numbers)
print("平均: {:.1f}:".format(avg1))
sum = 0
for num in numbers:
sum += (num - avg1) ** 2
print("分散: {:.1f}".format(sum / len(numbers)))
(2)sum関数を使う
avg2 = sum(numbers) / len(numbers)
print("平均: {:.1f}".format(avg2))
total = 0
for num in numbers:
total += (num - avg2) ** 2
print("分散: {:.1f}".format(total / len(numbers)))
(3)リストの内包表記とsum関数を使う
numbers = [3, 5, 6, 6, 10]
avg3 = sum(numbers) / len(numbers)
print("平均: {:.1f}".format(avg3))
print("分散: {:.1f}".format(sum([(num - avg3) ** 2 for num in numbers]) / len(numbers)))
関数宣言(定義)さえ覚えればもっとすっきりしたコードが書けます。共分散、相関係数などロジック自体は数行というところです。内包表記は強力なツールですね。
2017-08-05(土) 【Java/Servlet】生のServletで画像ファイルをダウンロード
JavaでWebアプリを作るとなるとSpringなどのフレームワークを使っている方も多いと思います。今日はフレームワークを使わずServletで画像ファイルをダウンロードする方法の紹介です。
画像ファイルは<img src="xxx.jpg" alt="yyy" />で十分な場合もあります。しかし、パスを明かしたくない場合もあるかと思います。そのような場合、img要素のsrc属性に画像ファイルのパスを指定するのではなく、画像ファイルの出力に特化したServletを使えば簡単です。
Servletを呼び出すコードは以下の通りです。src属性はServletのurlパターンです。
<img src="/selfjsp2/fileout" alt="教室画像" />;
ServletのdoGetメソッドのコードは以下のようになります。ポイントはresponseからgetWriterでPrintWriterを取り出すのではなく、getOutputStreamでServletOutputStreamを取り出すところです。あとはjava.ioパッケージの定番のクラスを組み合わせることになります。
response.setContentType("image/jpeg");
ServletOutputStream servletOutput = response.getOutputStream();
ServletContext app = this.getServletContext();
String realpath = app.getRealPath("/WEB-INF/data/xxx.jpg");
BufferedInputStream inputStream
= new BufferedInputStream(new FileInputStream(realpath));
byte[] buf = new byte[256];
int len;
while((len = inputStream.read(buf)) != -1) {
servletOutput.write(buf, 0, len);
}
servletOutput.flush();
servletOutput.close();
inputStream.close();
2017-05-27(土) 【SQL】where句で集計関数が使えない理由
select文のwhere句では集計関数が使えません。SQLの入門書ではその説明がありません。なぜならプログラミングの素養が必要だからです。where句はテーブルスキャンの場合、先頭の行から順に読み込み、条件式がtrueの行だけを抽出します。
データベースは速度が命です。一度、where句でふるいにかけてから集計しているようでは速度が出ません。読み込みつつ、合計、件数、最大値、最小値を計算しています。したがってwhereで行をふるいにかけている最中にはまだ合計、件数、最大、最小は求まっていません。だから使えないのです。プログラムをやっていればすぐに理解できる仕組みですね。ちなみに平均は合計を件数で除したものです。
以下のコードは、上記の動きを表すため、Javaで作った模擬的なコードです。for文が1件ずつ行を取り出す処理、その中のif(numbers[i] % 2 == 0)がwhere句だと考えてください。このようなwhere句は可能ですが、if(numbers[i] > avg)のようなwhere句が使えないことは自明ですね。
public static void main(String[] args) {
int[] numbers = { 34, 42, 90, 35, 20, 50, 92, 83, 20 };
if (numbers.length == 0) {
System.exit(-1);
}
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
int sum = 0;
int count = 0;
for (int i = 0; i < numbers.length; i++) {
if (numbers[i] % 2 == 0) {
sum += numbers[i];
count++;
if (max < numbers[i]) {
max = numbers[i];
}
if (min > numbers[i]) {
min = numbers[i];
}
}
}
System.out.println("合 計:" + sum);
System.out.println("平 均:" + (double)sum / count);
System.out.println("最大値:" + max);
System.out.println("最小値:" + min);
System.out.println("件 数:" + count);
}
2017-05-18(木) 【Java】Stream APIが使えないバージョンでは
5月13日ではStream APIを使用して、半径のリストからその面積を表示するプログラムの例を示しました。今回はリストの要素の偶数だけの合計値を求めてみます。
Integer sum = Stream.of(1, 2, 3, 4, 5)
.filter(n -> n % 2 == 0)
.reduce(0, Integer::sum);
System.out.println("合計:" + sum);
非常に簡潔に記述できます。ただし、まだ世の中の多くのJavaで作られたシステムはJava SE 7以前です。つまりStream APIを使用できません。では、どのようにすれば同等のことが出来るかを示します。
- リストの要素が集計の対象であることを判定する抽象メソッド(filter)をもったインタフェースを用意する
- 1.のインタフェースを実装した具象クラスを用意する。今回は偶数であれば対象と判定するfilterメソッドを実装する
- 1.のインタフェースと集計対象となるリストを引数として受け取るメソッドを用意する
1.インタフェース(MyArrayFilter)を用意する
public interface MyArrayFilter {
public boolean filter(int num);
}
2.1のインタフェースを実装したクラス(MyArrayFilterEven)を用意する
public class MyArrayFilterEven implements MyArrayFilter {
@Override
public boolean filter(int num) {
return num % 2 == 0;
}
}
3.1のインタフェースとリストを受け取る集計メソッドを用意する
public class MyArrayFilterTest {
public static void main(String[] args) {
List list
= Arrays.asList(1, 2, 3, 4, 5);
System.out.println("合計:"
+ sum(new MyArrayFilterEven(), list));
}
public static int sum(MyArrayFilter filter,
List list) {
int sum = 0;
for(int n : list) {
if (filter.filter(n)) {
sum += n;
}
}
return sum;
}
}
上記リストのmainメソッドでテストしています。結果はStream APIを使用した場合よりも用意するものが多く、煩雑に見えますが、面白い解き方であると個人的には感じています。
2017-05-13(日) 【Java】Stream API
5月7日のPythonの内包表記をJavaのStreamを使うと以下のように書けます。Javaの記法は煩雑だと敬遠される時期もありましたが、やっと追いついてきた感じです。
Stream.of(1, 2, 3, 4, 5)
.map(n -> Math.PI * n * n)
.forEach(System.out::println);
2017-05-07(日) 【Python】リストの内包表記
Pythonの内包表記は簡潔で強力なコレクションクラスの生成方法です。半径のリストからその面積のリストを生成し表示するスクリプトです。非常にスマートな記述になります。
import math
radiuses = [1, 2, 3, 4, 5]
for area in [r**2*math.pi for r in radiuses]:
print(area)
2017-05-03(水) 【Java】サーバ移転時のジャンプ
サーバの移転などでドメインを変更した場合、古いドメインからいきなりジャンプすると、ドメイン名が変更されたことにユーザが気付くことが出来ません。
直接的な対処方法としては、「10秒後に新しいサイトに自動的にジャンプします」などのメッセージを表示して、新しいドメインにジャンプすることです。この方法であればユーザはドメイン名の変更に気付くことが出来、ジャンプ後のURLをブックマーク(お気に入り)に登録しなおしてもらうことが出来ます。
今ではJavaScriptで行うことが多いと思いますが、サーバサイドの言語でも可能です。以下はJSPを使ったサンプルコード(スクリプトレットのみ)です。
<%
Integer count = session.getAttribute("count") == null? 10:
(Integer)session.getAttribute("count");
response.setIntHeader("Refresh", 1);
out.println(count + "秒後にジャンプします。");
if (count <= 0) {
session.invalidate();
response.sendRedirect("https://haru-idea.jp");
} else {
count--;
session.setAttribute("count", count);
}
%>
2017-05-02(火) 【Python】高階関数
JavaやC#と違い、Pythonの関数はもともと第1級関数であるので、関数の引数として関数を渡したり、戻り値(返り値)と関数を返すことも可能です。したがって、C#でデリゲートを使ったプログラムも以下のように簡単に記述できます。
def sum(func, array):
result = 0
for n in array:
if (func(n)):
result += n
return result
def even(n):
return n % 2 == 0
print(sum(even, numbers))
2017-04-30(日) 【C#】lambda式
4月28日のデリゲートをラムダ式に置き換えたサンプルです。メソッド定義すら要らなくなります。Sumメソッドの引数としてラムダ式を渡すだけで任意の条件で集計可能になっていることに気づかれたでしょうか?
class Program
{
// 集計対象の配列
static int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
/*
* 引数がint型で戻り値がbool型のデリゲートの宣言
* Funcでも可能ですが・・・
*/
delegate bool Cond(int n);
static void Main(string[] args)
{
Console.WriteLine(Sum((n) => { return true; }));
Console.WriteLine(Sum((n) => { return n % 2 == 0; } ));
Console.WriteLine(Sum((n) => { return n > 5; } ));
}
// Cond型のラムダ式を引数に取る集計メソッド
static int Sum(Cond c)
{
int sum = 0;
foreach (int n in numbers)
{
if (c(n))
{
sum += n;
}
}
return sum;
}
}
2017-04-28(金) 【C#】Delegate
C#独自の機能というわけではありませんが、デリゲートという仕組みがあります。メソッドの引数構成や戻り値が同じであれば、デリゲートに代入し、同じような処理にロジックを注入できるという仕組みです。
以下は配列に存在する数を集計するプログラムです。もっとスマートな解き方が既にC#にはありますが、デリゲートを理解するのに適したサンプルだと考えています。
単純に集計をするだけならばデリゲートは不要ですが、配列からある条件を満たしたものを集計したい場合、条件式だけが変化することに気付けば、その条件式のロジックをデリゲートを介し集計(Sum)メソッドに注入することが可能です。デリゲートのおかげで似たような集計メソッドを作る必要がなくなります。
ラムダ式を使えばとか、Linqを使えばとかご指摘はあるかと思いますが、あくまでデリゲート理解としてのサンプルです。
class Program
{
// 集計対象の配列
static int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
/*
* 引数がint型で戻り値がbool型のデリゲートの宣言
* Func<int, bool>でも可能ですが・・・
*/
delegate bool Cond(int n);
static void Main(string[] args)
{
Console.WriteLine(Sum(TrueOnly));
Console.WriteLine(Sum(Even));
Console.WriteLine(Sum(GreaterThan));
}
// Cond型のデリゲートを引数に取る集計メソッド
static int Sum(Cond c)
{
int sum = 0;
foreach(int n in numbers)
{
if (c(n))
{
sum += n;
}
}
return sum;
}
// 常にtrueを返すメソッド
static bool TrueOnly(int n)
{
return true;
}
// 引数が偶数の場合trueを返すメソッド
static bool Even(int n)
{
return n % 2 == 0;
}
// 引数が5より大きい場合trueを返すメソッド
static bool GreaterThan(int n)
{
return n > 5;
}
}
2017-04-26(水) 【Python】Dictionary型
PythonのDictionary(辞書)型は、JavaではMap、JavaScriptやPHPでは連想配列、RubyではHashなどと呼ばれます。キーが分かれば瞬時にそれに紐づく値を引き出せるという優れものです。プログラム言語には欠かせないもので、Dictionary型をいかに使いこなすかが初級コースの目標の一つでもあります。
非常に便利なものではありますが、キーはイミュータブルなオブジェクトでなければならないことに要注意です。つまり、いったん値が決まったら、それ以降絶対値が変更できないという性質を持っていなければなりません。なぜなら、そのオブジェクトが持つ値を元にハッシュ関数が、キーに紐づく値となるオブジェクトのメモリのアドレスを求めるからです。
したがって、オブジェクトを不変に保てるような値がキーとして好まれるため、文字列や整数値が使用されることが多くなります。Pythonも他の言語と同じように作るのはいたって簡単です。以下のコードは曜日の英和辞書を和英辞書に変えるスクリプトです。
# 曜日の英和辞書を作る
day_of_week_en = {'Sun': '日', 'Mon': '月', 'Tue': '火',
'Wed': '水', 'Thu': '木','Fri': '金', 'Sat': '土'}
print(day_of_week_en)
# 和英辞書へ変換する
day_of_week_ja = {}
for en, ja in day_of_week_en.items():
day_of_week_ja[ja] = en
print(day_of_week_ja)
2016-11-25(金) 【SQL】絞り込み後のグループ化でグループが欠落することを回避する方法(別解)
11月23日のSQLの問題はあくまで解き方の1つです。他にも方法はあります。1年ほど前に他の生徒さんと考えたSQLは以下の通りです。これも面白い解き方ですね。少し技巧的ですが、自分の頭で解いているなと感じられます。
select A.地域名,
case when coalesce(B.店舗数, 0) > A.店舗数 then coalesce(B.店舗数)
else A.店舗数
end as 店舗数
from
(
select distinct 地域名, 0 as 店舗数
from 地域
) as A
left outer join
(
select 地域名, count(支店名) as 店舗数
from 地域
where 支店名 like '%カフェ%'
group by 地域名
) as B
on A.地域名 = B.地域名
order by A.地域名;
2016-11-23(水) 【SQL】絞り込み後のグループ化でグループが欠落することを回避する方法
以下のような地域テーブルがあります。この中から支店名に「カフェ」つく店舗が地域ごとにいくつあるかを求める問題です。
| id | 支店名 | 地域名 | 社員数 | 店舗面積 |
|---|---|---|---|---|
| 1 | 総菜屋札幌支店 | 地域1 | 60 | 520 |
| 2 | レストラン山形支店 | 地域1 | 95 | 758 |
| 3 | 総菜屋日本橋本店 | 地域2 | 126 | 1108 |
| 4 | 総菜屋新宿支店 | 地域2 | 60 | 801 |
| 5 | 喫茶室渋谷店 | 地域2 | 102 | 988 |
| 6 | カフェ新潟支店 | 地域2 | 50 | 650 |
| 7 | 喫茶室大阪支店 | 地域3 | 120 | 850 |
| 8 | レストラン京都支店 | 地域3 | 46 | 690 |
| 9 | 総菜屋高松支店 | 地域4 | 55 | 450 |
| 10 | カフェ広島支店 | 地域4 | 67 | 520 |
| 11 | レストラン博多支店 | 地域4 | 86 | 569 |
| 12 | カフェ宮崎支店 | 地域4 | 35 | 483 |
参考書の答えは以下の通りです。
select 地域名, count(支店名)
from 地域
where 支店名 like '%カフェ%'
group by 地域名
その結果が以下の通りです。
| 地域名 | 店舗数 |
|---|---|
| 地域2 | 1 |
| 地域4 | 2 |
このような解答で業務要件を満足すればそれでいいでしょう。しかし、この解答では、地域2と地域4のほかにどのようなグループがあるのかが明らかではありません。
以下のような結果が欲しい場合のSQLを考えてください。
| 地域名 | 店舗数 |
|---|---|
| 地域1 | 0 |
| 地域2 | 1 |
| 地域3 | 0 |
| 地域4 | 2 |
生徒さんと一緒に考えた答えは以下の通りです。カフェがつく支店がないグループも表示されており、分かりやすい結果だと思います。
select A.地域名, sum(A.カフェ有無) as 支店数
from
(select 地域名,
case when 支店名 like '%カフェ%' then 1
else 0
end as カフェ有無
from 地域) as A
group by A.地域名;
いかがでしょうか?最初は難しく感じるかもしれませんが、初級コースを終わるころには難しくはなくなっているはずです。一緒に学びましょう!
2016-11-11(金) 【Java】和暦の表示方法
日本のシステムでは和暦を表示する必要がまだまだあります。特に官公庁では必須です。Javaの場合、自作しなくともLocaleオブジェクトでvariantを指定することで対応可能です。通常Localeオブジェクトは第2引数までですが、第3引数に「JP」を指定し、書式でyyの前にGGGGと指定すると2016年11月11日時点では「平成」、GGGと指定すると「H」と表示されます。意外と重宝しますので、以下のメソッドをご参考までに。
/**
*
* @param date @see java.util.Date
* @param isZeroPadding ゼロパディングする場合はtrue、しない場合false
* @return 和暦年月日 ゼロパディングする場合の例) 平成07年06月10日(土)
* ゼロパディングしない場合の例) 平成7年6月10日(土)
*/
public static String getWarekiStr(Date date, boolean isZeroPadding) {
final String ZERO_PADDING = "GGGGyy年MM月dd日(EEE)";
final String NOT_ZERO_PADDING = "GGGGy年M月d日(EEE)";
String format;
if (isZeroPadding) {
format = ZERO_PADDING;
} else {
format = NOT_ZERO_PADDING;
}
SimpleDateFormat sdf = new SimpleDateFormat(format, new Locale("ja", "JP", "JP"));
return sdf.format(date);
}
2016-10-14(金) 【SQL】MySQLではIN述語の後にORDER BY句を使用したサブクエリは使用できない
SQLの参考書の中には特定のRDBMS製品に特化したものもありますが、私の場合、あえて一般的なSQLの参考書を使用しています。その場合、困るのは参考書通り実行してもエラーになる場合です。
私が困るわけではなく、生徒さんが困るわけですが、そういう状況に出くわした場合にどう対応するかを学んでほしいのです。たとえば「スッキリわかるSQL入門」p232の2の問題は解答通りには動きません。
練習問題の概要をざっくりと説明します。牛の個体識別テーブルと頭数集計テーブルが出てきます。個体識別テーブルは個体識別番号、出生日、雌雄コード(1が雄、2が雌)、母牛番号、品種コード、飼育県の列で構成され、頭数集計テーブルは個体識別テーブルの飼育県と飼育県毎の頭数を集計した列で構成されています。
質問は「頭数集計テーブルのうち、飼育頭数の多い方から3県に限っての牛の情報を個体識別テーブルから取得せよ」というものです。本書の解答は以下の通りです。
select 飼育県 as 都道府県名, 個体識別番号,
case 雌雄コード when '1' then '雄'
when '2' then '雌'
end as 雌雄
from 個体識別 as K
where 飼育県 in (select 飼育県 from 頭数集計 order by 頭数 desc limit 3);
多くのRDBMSではこのままで正常に動くのですが、MySQLではIN述語の右側のサブクエリの中でORDER BYを使うとエラーになるのです。みなさんならどうやって解きますか?実はこのあたりの解き方に慣れるとSQLを読み書きする能力が飛躍的に向上します。まずは考えてみてください。分からない場合は以下の私の解答例を見てください。
select K.飼育県 as 都道府県名, K.個体識別番号 as 個体識別番号,
case K.雌雄コード when '1' then '雄'
when '2' then '雌'
end as 雌雄
from 個体識別 as K
where exists
(select * from (select * from 頭数集計 order by 頭数 desc limit 3) as A
where A.飼育県 = K.飼育県);
どうでしたか?分かりましたか?分からない場合は、SQLに関してはまだ初級者だと思われます。一緒に勉強してみませんか。データを操作する楽しさを共有しましょう!
2016-09-05(月) 【JavaScript】addEventListenerでイベントの伝播方向を指定する
イベントハンドラを登録するには下記の3つの方法があります。
(1) タグの属性として記述する方法
<input type="button" id="btn" value="XXX" onclick="abc()" />
(2) 要素のプロパティに関数を登録する方法。イベントハンドラは下記のように関数リテラルでも、function命令の関数でも構いません。
window.onload = function() {
document.getElementById('btn').onclick = function() {
// 処理
};
};
(3) イベントリスナーによる登録する方法
window.addEventListener('load', function() {
document.getElementById('btn').addEventListener('click', function() {
// 処理
}, true);
});
上記(1)や(2)の登録方法ではできない、以下のことが実現可能です。
- 同じ要素の同じイベントに対する複数のイベントハンドラの登録が可能
- イベントを文字列として指定するため、将来開発される未知のイベントにも対応可能
- イベントハンドラの登録解除が可能
- イベントの伝播方向を制御可能
イベントの伝播方向はaddEventListenerの第3引数で指定します。trueの場合、上位からターゲット要素までのEvent Capturing、falseの場合、ターゲット要素から上位要素方向へのEvent Bubblingとなります。
2016-08-29(月) 【Java】Queue構造としてArrayListが向いていない理由
Queue構造を実装するのにLinkedListではなくArrayListでも構わないのかという質問を先週受けました。
確かに両者ともListインタフェースを実装していますが、中の作りが全く異なります。ArrayListは名前の通り、内部に配列を保持しています。つまりインデックス操作によりアクセスをしています。
一方LinkedListはフィールドにprivateな内部クラスであるNodeの参照を2つ持っています。一つは先頭のNodeの参照、もう一つは末尾の参照です。
さらにNodeクラスの内部はフィールドとしてNodeの参照を2つ持っています。一つは次のNodeの参照を保持し、もう一つは前のNodeの参照を持っています。つまりLinkedListはインデックス操作ではなく、参照をたどることにより前後に移動します。
ここからが本題です。インデックス操作するArrayListと参照をたどる操作をするLinkedListの決定的な違いはなんでしょうか?
ArrayListをQueue構造に使用すると、先頭から要素を削除した場合、インデックスを1つずつずらす操作が必要になります。件数が多いときは明らかに効率が悪いですね。 それに対しLinkedListは、Nodeオブジェクトのnextとpreviousをつなぎかえる作業をするだけです。件数とは全く関係ありません。先頭と末尾を管理している、しかも削除しても全体には影響を与えず、2番目の要素と末尾の要素のリンクの貼り直しだけで済みます。LinkedListの方がQueueに向いていることは明らかですね。文章だけで説明したため、すっきりしない場合、LinkedListのソースコードを読むことをおススメします。
2016-08-27(土) 【JavaScript】既存のclassを消去することなくclassを追加、置換する方法
JavaScriptからStyleを操作するにはインラインでstyle属性を直接指定する方法や、class属性を操作することによりCSSを適用する方法があります。
class属性を操作する場合、不用意に値を代入することは危険です。既存のclassを消去することになるからです。最近のフレームワークは要素に対し勝手にclassを追加するため、代入で消してしまうとフレームワークが正常に動作しなくなります。
これを解決する方法はいろいろあるかと思いますが、配列操作のいい練習になるため、配列を使って解決する方法を紹介します。あくまでも一例なので状況に応じて変更してください。
CSSを用意します。ただしhilight、normal、abortは同時に適用されることがないと仮定します。
.hilight {
background-color: pink;
}
.normal {
background-color: white;
}
.abort {
background-color: red;
}
JavaScriptでイベントハンドラを定義します。(addEventListenerでの定義を知ってる方は適宜書き換えてください)
function changeStyle(elem, clazz) {
// 第2引数のclazzでの置き換え対象を配列で定義
var targetClasses = ['hilight', 'normal', 'abort'];
// 既存のclassを半角空白を区切り文字(delimiter)として配列へ変換
var result = elem.className.split(' ');
// 最初は置き換え対象が存在しないので、置き換えたか判定するためのフラグを用意
var replace_flag = false;
outer:
for (var i = 0; i < result.length; i++) { // 既存のclassの配列を回す
for (var j = 0; j < targetClasses.length; j++) { // 置換対象を回す
if (targetClasses[j] === result[i]) { // 置換対象を探す
result.splice(i, 1, clazz); // 見つかったら置換する
replace_flag = true; // 置換したらフラグをONにする
break outer; // 外側のfor文を抜ける
}
}
}
if (!replace_flag) { // 置換していない場合、末尾に追加
result.push(clazz);
}
// 半角空白で文字列へ変換し、class(JavaScriptの場合、className)に代入
elem.className = result.join(' ');
}
HTML、body部の記述。既存のclassを消去しないか確認するため、clazz1とclazz2をclassに指定しておきます。
<div class="clazz1 clazz2"
onclick="changeStyle(this, 'abort')"
onmouseover="changeStyle(this, 'hilight')"
onmouseout="changeStyle(this, 'normal')">
classNameに不用意に代入していないか?
</div>
Chromeをはじめとしたブラウザで検証してください。clazz1やclazz2はそのままで、hilihgt、normal、abortが入れ替わっている様子が分かるはずです。冗長な書き方ですが、簡単は配列操作でも実現可能です。
2016-08-24(水) 【Python】matplotlibで描画処理
今日は無料体験授業の日なので実際の授業はやっていません。しかし、来年コースにしたいPythonの勉強をしています。一通り「Introducing Python」で基本を復習したので、今は「Doing Math with Python」で少し応用が利く分野にチャレンジ中です。
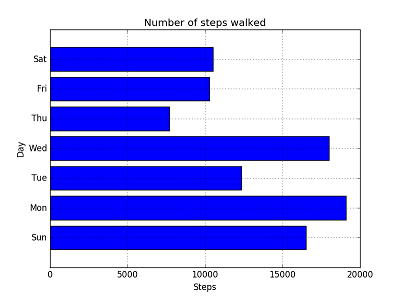
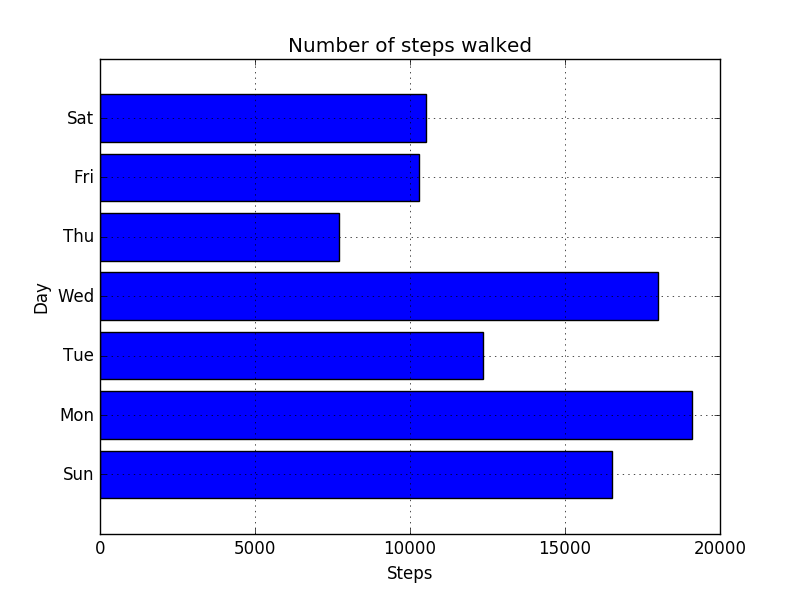
以下の図はmatplotlibのpyplotでバーチャートを描画した結果です。先週の曜日毎の歩数をバーにしています。何か形として見える学習は楽しいですね。
2016-08-24(水) 【SQL】運用任せのSQLは避けるべき
SQL初級コースは「スッキリわかるSQL入門」を教材として使用しています。もちろん、市販の教科書は実務では避けたいようなことが書かれています。
たとえば第3章の問題3-3は非常に不適切な問題です。でも、こういう不適切な問題があるからこそ、このように解いてはダメと言えるのです。きちんと指導してくれる先生がいるとかえってこのような問題が理解力を深めると考えています。このあたりが独学の限界ですね。
問題3-3をざっくり説明します。成績表テーブルがあり、列として名前、法学、経済学、哲学、情報理論、外国語、総合成績があります。総合成績は最初nullです。名前以外の科目は点数が格納されています。その点数をもとに以下の条件で総合成績を求めます。
- (1) 全科目が80以上の学生は「A」とする。
- (2) 法学、外国語のどちらかが80以上で、経済学、哲学のどちらかが80以上は「B」とする。
- (3) 全科目が50未満の学生は「D」とする。
- (4) それ以外の学生を「C」とする。
最初この問題を見たときは「おっ、いい問題だ」と思いましたが、解答をみたら愕然としました。このSQLを実務で運用していくのは困難だからです。以下が解答のSQLです。
-
(1) UPDATE 成績表 SET 総合成績 = 'A' WHERE 法学 >= 80 AND 経済学 >= 80 AND 哲学 >= 80 AND 情報理論 >= 80 AND 外国語 >= 80; -
(2) UPDATE 成績表 SET 総合成績 = 'B' WHERE (法学 >= 80 OR 外国語 >= 80) AND (経済学 >= 80 OR 哲学 >= 80) AND 総合成績 IS NULL; -
(3) UPDATE 成績表 SET 総合成績 = 'D' WHERE 法学 < 50 AND 経済学 < 50 AND 哲学 < 50 AND 情報理論 < 50 AND 外国語 < 50 AND 総合成績 IS NULL; -
(4) UPDATE 成績表 SET 総合成績 = 'C' WHERE 総合成績 IS NULL;
問題点に気づかれたでしょうか?問題は総合成績を求めるのに4つのUPDATE文が必要で(1)から順に実行しないと正常に働かない。
さらに重大な欠点は(2)、(3)、(4)の IS NULL の判定です。つまり、どこか1つでも成績を修正したら、一旦以下の手順でもう一度総合成績を求める必要があるのです。
- すべてのレコードの総合成績をnullにする
- (1)のUPDATE文を実行する
- (2)のUPDATE文を実行する
- (3)のUPDATE文を実行する
- (4)のUPDATE文を実行する
運用で縛らなければならないSQL文は最悪です。解答を見ただけでこれに気付く生徒さんは一握りです。独学の怖さがここにあります。これをシンプルに解くにはCASE演算子が一番ふさわしいと思います。皆さんも挑戦してください。
2016-08-23(火) 【Java】【JavaScript】JavaScriptからJava ServletへのJSONの受け渡し
jQueryやAngularなどのライブラリーやフレームワークはほとんどJSONの存在を意識することなくJavaScriptとサーバサイドの言語のやり取りができます。
ある生徒さんがそういうフレームワークを使わずシステムを作りたいというので久しぶりに生のJavaScriptと生のServletで挑戦。
クライアントサイド
// JSON.stringifyの引数は実際にはプログラムで作成
var members = JSON.stringify([
{"name":"Tomoharu Kawakubo", "age": "45"},
{"name":"Taro Yamada", "age", "33"}
]);
var xhr = new XMLHttpRequest();
// abcはServlet側のcontext root, regist-memberはurl-patterns
xhr.open("POST", "/abc/regist-member");
xhr.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
xhr.send(members);
サーバサイド
JavaScriptのオブジェクトをJavaBeansへ変換。配列も配列へ変換できます。JSONICは直感的でいいですね。
StringBuilder sb = new StringBuilder();
BufferedReader reader = request.getReader();
String line;
while((line = reader.readLine()) != null) {
sb.append(line);
}
// MemberBeanはnameとageをフィールドにもつJavaBeans
MemberBean[] bean = JSON.decode(sb.toString(), MemberBean[].class);
2016-08-22(月) 【PHP】感動する力
PHPを勉強し始めて間もない生徒さんに、年齢と性別を入力して料金を計算するプログラムを作ってもらいました。
A.phpからB.phpにデータを送り、if文の入れ子で料金を求めるというだけの極めてシンプルなものですが、非常に感激してもらい、こちらまで嬉しくなりました。よく思うのですが、「感動する力」は能力を伸ばすための大きなエネルギーです。この気持ちを忘れないでください。
2016-08-21(日) 【JavaScript】setIntervalとsetTimeoutを使った移動サイトへのジャンプの仕方
サイトのURLを変更したとき「当サイトは下記リンクへ移動しました。下記リンクをクリックするか、10秒後に自動的にジャンプします」のようなメッセージが出てきますが、setIntervalとsetTimeoutメソッドを使うと簡単に実装できます。
ジャンプする前にclearIntervalでインターバル処理をストップします。コードは載せません。是非、挑戦してください。
2016-08-20(土) 【Java】内部クラス
内部クラスの詳しい話をする前に、既に内部クラスを持ったクラスを使用していることをArraysクラスやLinkedListクラスを例に説明しました。
// 配列からリストへの変換
String[] aaa = {"春", "夏", "秋", "冬" };
List<String> bbb = Arrays.asList(aaa);
// リストから配列への変換
String[] ccc = bbb.toArray(new String[] {});
ArraysクラスにはArrayListというトップレベルクラスと同名の内部クラスが定義されており、これがasListメソッドの戻り値として返されています。興味のある方はご確認ください。
2016-08-19(金) 【Java】ListとSetのcontainsメソッドの性能
ListとSetにはcontainsと呼ばれる引数で指定したオブジェクトが存在するかを判定するためのメソッドがあります。入門書では詳しく解説されていませんが、データ件数が大きくなればなるほど検索速度に劇的な差が出ます。
1から10億までに存在する乱数をListとSetに100万件格納し、1から10億までの乱数を発生させ、ナノ秒単位で計測してみてください。アルゴリズムを知らなくともこの差を体感してもらっています。コレクションクラスは使いどころを理解することが肝要です。
JavaのSetはPythonほど高機能ではありませんが、ホワイトリスト・ブラックリストの実装には最適です。お試しください。
2016-08-18(木) 【JavaScript】オブジェクトリテラルでメソッドを追加
一般的にメソッドはprototypeにオブジェクトリテラル形式で登録するのがよいと言われています。しかし、よく考えると分かりますが、オブジェクトリテラル形式でprototypeに代入すると継承(プロトタイプチェーン)が切れてしまいます。
継承したのちに、ドット演算子で追加した方が無難でしょう。AAA.prototype.__proto__ = new BBB()のようにやれなくもないですが直接__proto__に代入するのは好ましくありません。JavaScriptの継承は意外と厄介ですね。